운영 서버에 무중단 배포 적용하기
이 글은 우아한테크코스 백엔드 6기 도비에 의해 작성되었습니다.
안녕하세요 팀 크루루의 백엔드 도비입니다! 이번 포스팅에서는 우리 팀에서 적용한 무중단 배포에 관해서 설명해 보고자 합니다.
기존 배포 방법
저희 크루루 백엔드팀은 운영서버에 새로운 버전의 API가 배포될 때도 끊김이 없는 사용자 경험을 위해 무중단 배포를 적용하기로 했습니다.
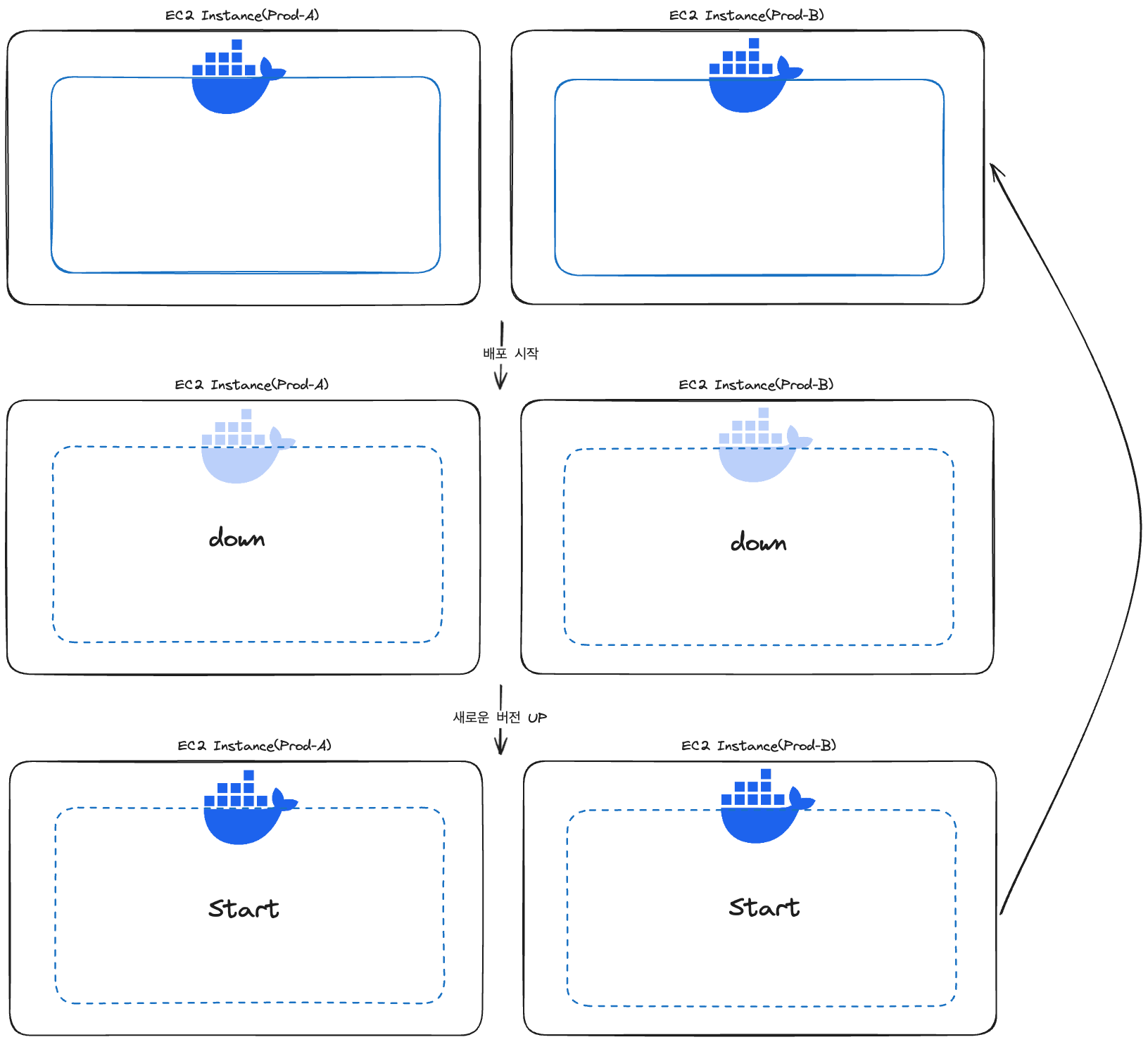
기존의 배포 방법은 Github Actions를 이용한 배포였는데요. 2개의 AWS EC2 인스턴스 내에서 Dockerize되어 컨테이너 환경 위에서 실행 중인 API 서버를 동시에 내리고, 동시에 다시 올리는 방식이었습니다.
각각의 인스턴스가 Github Actions의 self-hosted 환경으로 이용되고 있습니다.
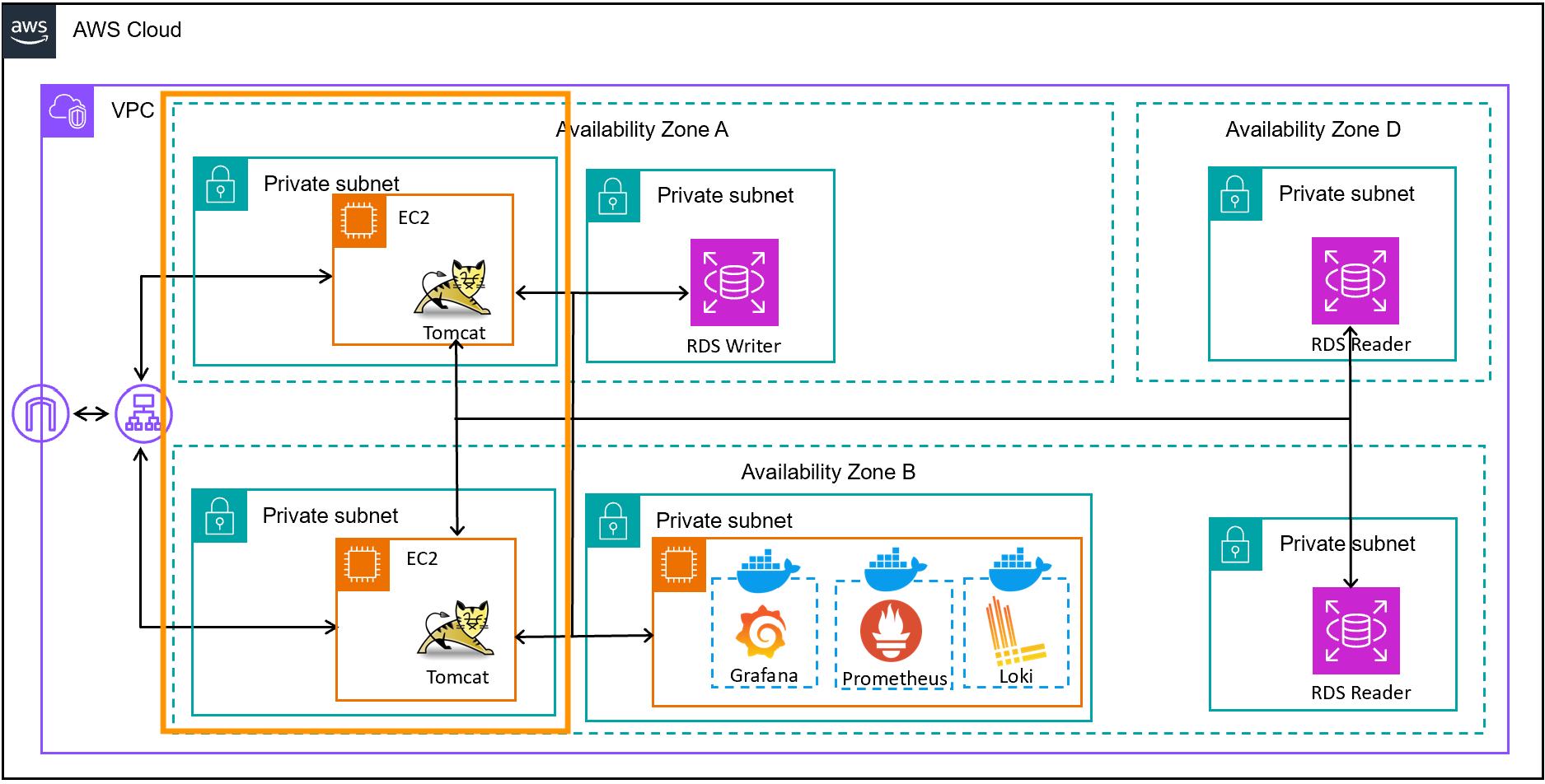
metrix 키워드가 적용된 workflow 스크립트를 이용하여 release branch에 새로운 버전으로 Push가 이루어지면 병렬적으로 배포가 이루어졌습니다. 배포가 진행되는 동안에는 EC2 인스턴스는 실행되고 있는 상태지만, 그 안에서 돌아가고 있는 Docker Container가 일시적으로 stop 되기에 새로운 버전의 docker image가 적용된 Container가 다시 up 될 때까지 서버는 API 처리를 하고 있지 못했습니다.
deploy:
environment: prod
strategy:
max-parallel: 2
matrix:
runners: [be-prod-a, be-prod-b]
runs-on: [self-hosted, '${{ matrix.runners }}']
needs: build
고려 사항
1. 배포 단위: AWS EC2 인스턴스 vs Docker Container
AWS EC2 인스턴스를 통째로 최신 버전의 백엔드 컨테이너가 돌아가고 있는 인스턴스 단위로 갈아 끼우느냐, 아니면 인스턴스는 그대로 두고 그 안에서 실행되고 있는 Docker Container를 갈아 끼우느냐의 선택이었습니다.
기존에 우테코에서 제공하고 있는 AWS IAM Role을 최우선 고려 조건으로 생각했습니다. 인스턴스 자체를 교체하는 것은 기존의 인스턴스를 삭제하는 것이 전제되어야 했기에, 비교적 권한으로부터 자유로운 Docker Container를 교체하는 것으로 결정하였습니다.
Docker Container만을 교체한다면, 인스턴스 환경을 Self-Hosted Runner 환경으로 사용하는 기존 Github Actions에서의 Workflow 스크립트만 변경하면 되는 일이었습니다.
다만, AWS의 인프라(ALB, Code Deploy 등)을 이용한다면 이미 구축되어 있는 무중단 배포 서비스를 이용할 수 있는 이점이 있었습니다. 또한 저희 2대의 EC2 인스턴스는 ELB를 통해 로드 밸런싱이 되고 있었기에, 배포가 되는 동안 ELB에서 요청을 돌려주는 기능을 사용해야 하는 필요성도 있었습니다.
하지만
첫 번째, AWS IAM Role의 리소스 삭제 권한의 한계
두 번째, 기존 배포 Pipeline에서의 변경 최소화
를 근거로 Docker Container 단위로 무중단 배포를 진행하기로 했습니다.
그리고 기존의 ELB 사용하지 않는 대신, 인스턴스 내에 NginX 컨테이너를 두어 배포가 되는 과정에서의 요청을 인스턴스 내부에서 로드밸런싱하게 하였습니다. 이 부분에 관하여 본 포스팅 후반에서 다루고자 합니다!
이제 어떤 단위로 배포할지가 결정이 났으니, 무중단 배포 전략에 대해 의논했습니다.
2. 배포 전략 조사
1. Blue-Green 배포
- Blue-Green 배포는 두 개의 배포 환경(Blue 환경과 Green 환경)을 사용하여 배포를 관리.
- Blue 환경: 현재 서비스 중인 버전이 실행되고 있는 환경.
- Green 환경: 새로운 버전이 배포되는 환경.
새로운 버전이 Green 환경에 배포되고, Green 환경에서 모든 테스트가 완료되면 트래픽을 Blue 환경에서 Green 환경으로 전환. 전환 후 문제가 없으면 Green 환경이 새로운 Blue 환경이 되며, 기존의 Blue 환경은 테스트나 롤백을 위한 새로운 Green 환경으로 사용됩니다.
장점
** **1. 즉각적인 롤백 가능: 문제가 발생할 경우 트래픽을 바로 기존 Blue 환경으로 다시 전환하면 되므로 빠르게 롤백이 가능합니다.
- 테스트 용이성: 새로운 버전을 실제 서비스 트래픽과 격리된 Green 환경에서 테스트할 수 있습니다.
단점
- 자원 소모: Blue와 Green 두 개의 환경을 동시에 유지해야 하므로 서버 자원이 두 배로 필요합니다.
- 복잡성: 두 개의 환경을 관리해야 하므로 인프라 관리가 복잡해질 수 있습니다.
2. Rolling 배포
개념
Rolling 배포는 여러 개의 서버(혹은 인스턴스)가 있을 때, 각 서버에서 점진적으로 새로운 버전을 배포하는 방식입니다. 예를 들어, 10개의 서버가 있다면 한 번에 1~2개의 서버에만 새로운 버전을 배포하고, 그 서버들이 정상적으로 동작하면 나머지 서버로 순차적으로 배포를 진행합니다.
장점
- 자원 효율성: Blue-Green 배포처럼 두 배의 자원이 필요하지 않으며, 기존 서버들을 사용하여 점진적으로 배포합니다.
- 단일 환경 관리: 하나의 배포 환경에서 작업이 이루어지므로 인프라 관리가 상대적으로 단순합니다.
단점
- 롤백 어려움: 배포 도중 문제가 발생하면 이미 배포된 서버들을 다시 되돌리는 과정이 복잡할 수 있습니다.
- 일관성 문제: 모든 서버가 새로운 버전으로 업데이트되기 전까지는 같은 시간에 서로 다른 버전의 서버가 동시에 운영되므로 일관성 문제(특히 데이터베이스 스키마 변화 등)가 발생할 수 있습니다.
3. 카나리 배포
개념
카나리 배포는 새로운 버전을 전체 사용자에게 배포하기 전에 일부 사용자에게만 배포하여 테스트하는 방식. 보통 트래픽의 일정 비율(예: 5%, 10%)을 새로운 버전으로 전환하고, 이 작은 그룹에서 문제가 발생하지 않으면 점진적으로 더 많은 사용자에게 배포합니다. 카나리 배포는 사용자가 많거나 변경 사항의 위험도가 높은 경우에 자주 사용.
장점
- 위험 관리: 새로운 버전의 위험을 제한된 사용자 그룹에서 먼저 테스트할 수 있어, 문제 발생 시 영향 범위가 작습니다.
- 점진적 확장: 새로운 버전이 안정적임을 확인하면서 점진적으로 트래픽을 증가시킬 수 있습니다.
- 사용자 피드백 반영: 일부 사용자들로부터 먼저 피드백을 받아 필요한 경우 배포 전에 버그를 수정할 수 있습니다.
단점
- 복잡성: 트래픽을 분배하고 관리하는 데 추가적인 인프라와 설정이 필요합니다.
- 배포 속도: 모든 사용자에게 배포하기까지 시간이 오래 걸릴 수 있습니다.
- 테스트 범위 제한: 초기 트래픽이 제한되므로 특정 사용자 그룹에서만 발생하는 문제를 파악하기 어려울 수 있습니다.
각 전략의 비교
| 배포 방식 | 장점 | 단점 |
|---|---|---|
| Blue-Green | 즉각적인 롤백 가능, 테스트 용이성 | 자원 소모가 크고, 인프라 관리가 복잡 |
| Rolling | 자원 효율성, 단일 환경 관리 | 롤백이 어려움, 일관성 문제 발생 가능 |
| 카나리 | 위험 관리 용이, 점진적 확장 가능, 사용자 피드백 반영 가능 | 복잡한 설정, 배포 속도 느림, 테스트 범위 제한 |
무중단 배포 전략 선택
팀 크루루는 롤링과 Blue-Green을 둘 다 적용한 배포 전략을 선택하기로 했습니다.
이게 무슨 뜻이냐면, 앞서 설명한 배포 단위에 따라 전략을 다르게 두었다는 뜻입니다.
EC2 인스턴스와 인스턴스 내부의 Docker Container를 업데이트하는 방법을 각각 롤링과 Blue-Green을 채택했습니다. 인스턴스 단위로 보자면 인스턴스가 하나씩 업데이트 되는 롤링을 적용한 것이라고 볼 수 있지만, 보편적인 롤링과 확연하게 구분되는 점은 업데이트 되는 동안에도 해당 인스턴스가 요청을 계속 처리할 수 있다는 점입니다.
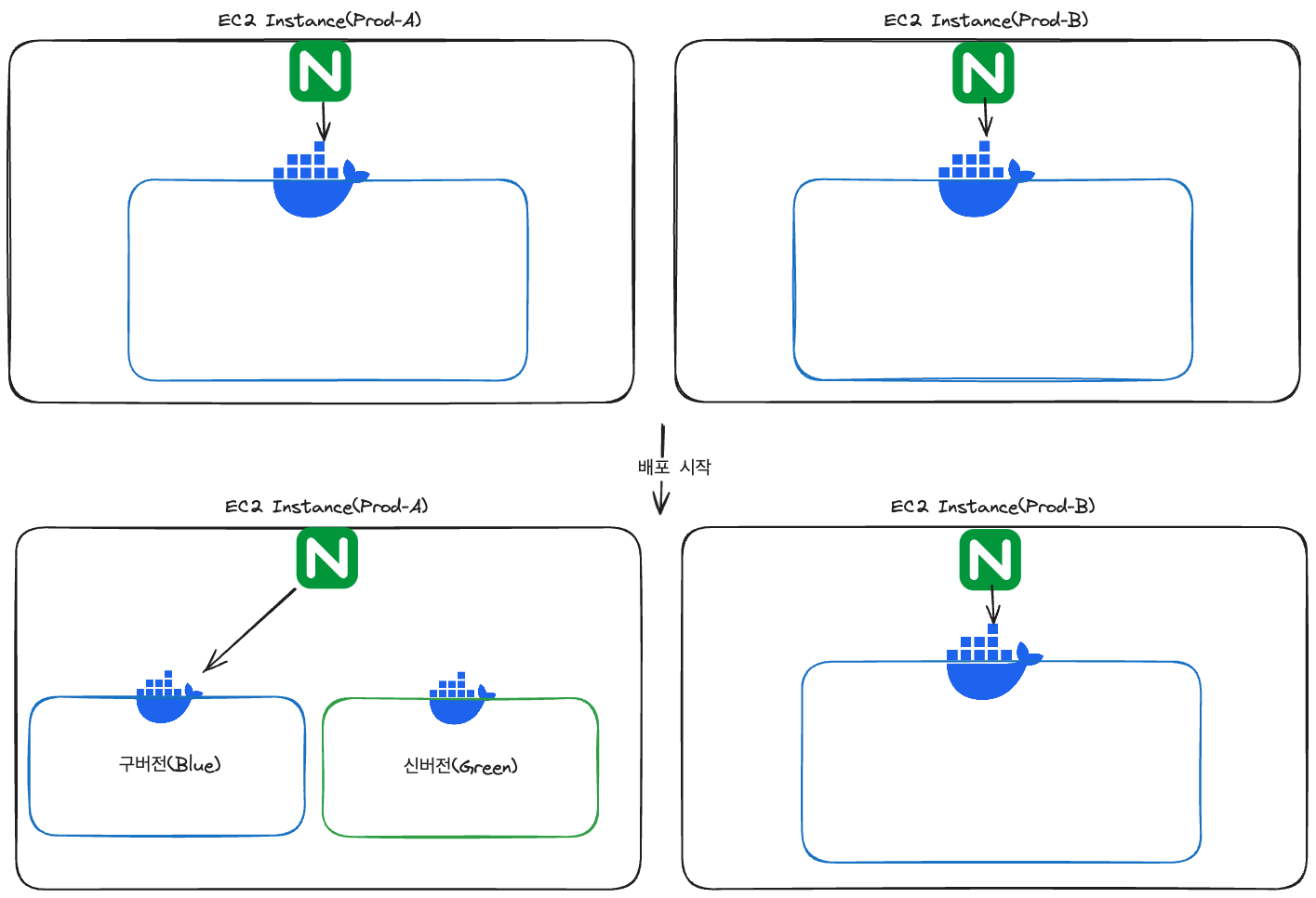
인스턴스 내부에서 실행되고 있는 Docker Container는 Blue-Green으로 업데이트 되어, 기존 컨테이너가 실행되고 있는 중에 새로운 버전의 컨테이너가 생성됩니다. 인스턴스 내부의 NginX가 요청을 기존 컨테이너로 보내고 업데이트가 끝나면 새로운 버전의 컨테이너로 요청을 보내며 구버전의 컨테이너를 제거하므로 2개 밖에 없는 인스턴스를 업데이트 중에서도 계속 요청을 처리할 수 있습니다.
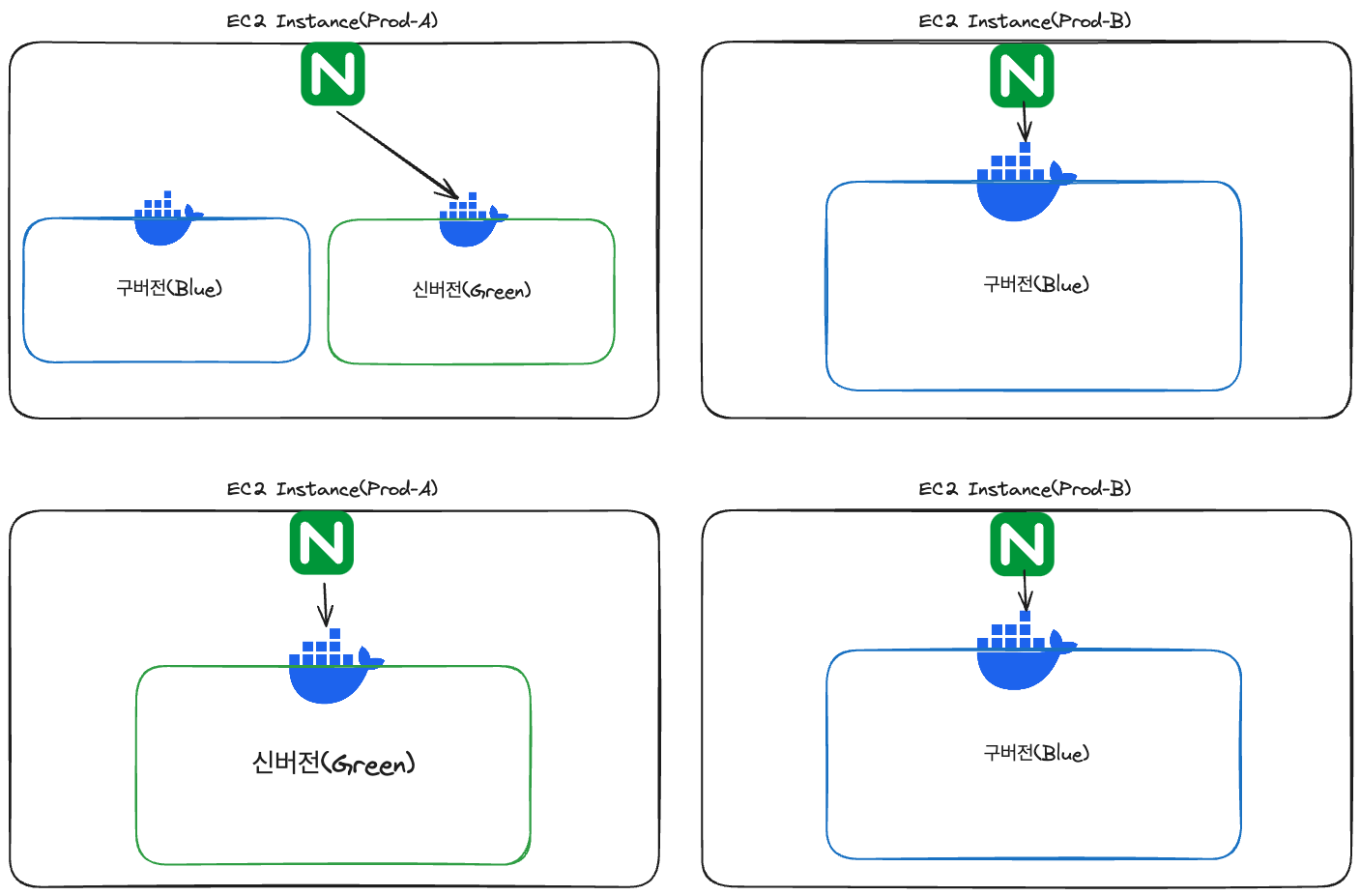
정리하자면 다음과 같은 이점을 가집니다.
- 부하 분산 유지: 2개뿐인 인스턴스를 하나라도 내리면 하나의 인스턴스가 모든 부하를 감당. 이 관점에서 기존의 부하 분산을 유지할 수 있다는 점.
- 비용 절감: 새로운 AWS 인프라 서비스를 도입하지 않기에 추가 비용이 없음.
- 유지보수에 용이: 기존 Github Actions로 관리되고 있던 배포 파이프라인을 유지할 수 있음.
무중단 배포 적용
우선, 기존에는 github의 release branch로 새로운 버전의 코드가 push되면 배포가 진행되도록 했습니다. 하지만 단순히 코드가 push가 되면 배포가 실행되는 방법은 안정적이지 않다고 생각되었습니다.
따라서, Github의 Releas와 Tag를 이용하여 새로운 버전에 대한 코드에 대해 Tag를 발행하고, 해당 Tag를 기준으로 개발자가 직접 배포를 진행하도록 바꿨습니다.
on:
workflow_dispatch:
inputs:
release-ver:
description: 'Release version tag (ex. v0.0.1)'
required: true
rollback-ver:
description: 'Rollback version tag (ex. v0.0.0)'
required: true
...
jobs:
# ...(build 과정)
deploy:
environment: prod
strategy:
fail-fast: true # 배포가 실패했을 때 전체 업데이트 중지
max-parallel: 1 # 인스턴스를 하나씩 업데이트(롤링 배포)
matrix:
runners: [be-prod-a, be-prod-b]
runs-on: [self-hosted, '${{ matrix.runners }}']
needs: build
다음은 수정된 배포 방식을 적용한 모습입니다.
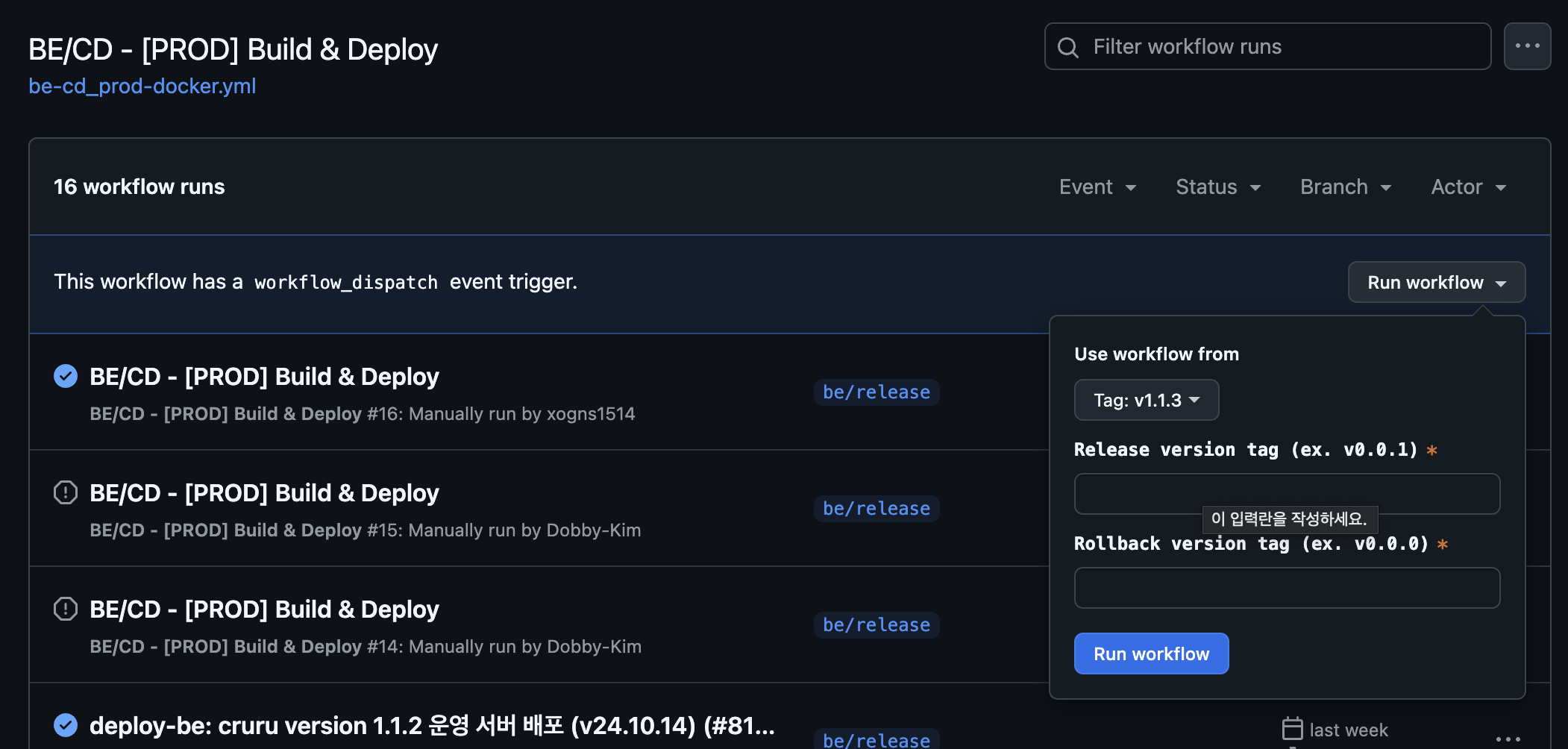
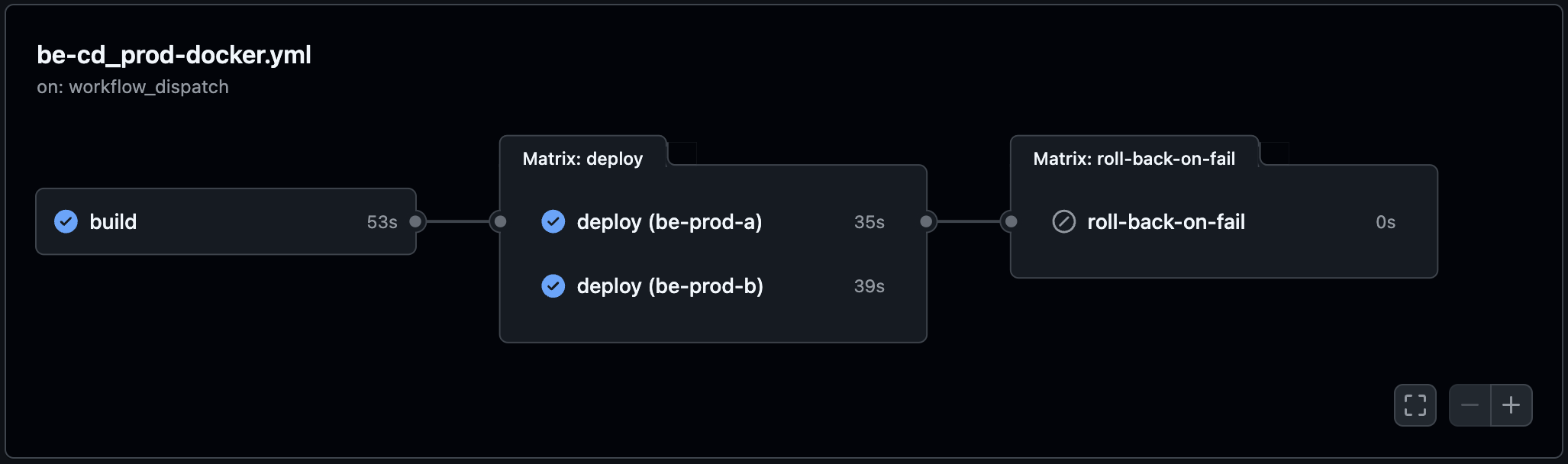
이미지에서 볼 수 있듯, 생성된 tag를 기준으로 배포를 진행하고, 롤백 버전을 직접 명시하여 배포를 실행하도록 했습니다.
Roll-Back
배포가 행복하게만 진행된다면 얼마나 좋을까요. 하지만 모종의 이유로 배포 버전에 문제가 있어 배포가 실패할 수도 있습니다. 이런 상황에서도 서비스는 안정적으로 운영되어야 하므로, 이미 문제없이 배포된 특정 버전으로 롤백을 진행하는 전략을 도입하기로 했습니다.
위의 이미지에서 볼 수 있듯, 생성된 tag를 기준으로 배포를 진행하고, 롤백 버전을 직접 명시하여 배포를 실행하도록 했습니다.
롤백은 무중단 배포 전략과 다르게, 인스턴스를 하나씩 롤백하는 것이 아닌, 모든 인스턴스를 동시에 롤백 버전의 컨테이너로 돌아 가게 했습니다.
배포가 실패되었다는 것은 실행이 되는 컨테이너에서도 심각한 결함이 존재할 수도 있다는 뜻이므로 배포가 되었던 모든 신버전 컨테이너를 다시 거두어 와야 한다고 판단했습니다.
roll-back-on-fail:
environment: prod
strategy:
matrix:
runners: [be-prod-a, be-prod-b] # 모든 인스턴스를 병렬적으로 처리
runs-on: [self-hosted, '${{ matrix.runners }}']
needs: deploy
if: failure() # 앞선 deploy 과정이 실패하면 실행되는 job으로 지정
잠재적 문제
다만 잠재적인 문제도 예상되었습니다.
- 인스턴스 자체 리소스 부족: 기존의 인스턴스는 Docker Container 하나만을 실행. 하지만 업데이트 시점에서는 기존 컨테이터 + 새로운 컨테이너 + NginX(상시 작동)가 실행되고 있기에 인스턴스의 부하가 가중될 수 있습니다.
- 연결된 인프라 리소스 부족: DB, Redis 등 서버와 직접적인 커넥션을 유지하고 있는 리소스들이 있습니다. 새로운 컨테이너가 실행되는 순간에 커넥션 풀의 개수가 부족해질 수도 있습니다.
- DB 스키마 불일치 문제: 만약 DB 테이블의 변경 점이 발생한다면, 기존 DB 테이블을 사용하고 있는 컨테이너와 새로운 버전의 컨테이너가 바라보고 있는 데이터가 다르기에 일관성에 문제가 발생할 수 있습니다.
하나씩 살펴보겠습니다.
1. 인스턴스 자체 리소스 부족
업데이트 시점에서는 기존 컨테이너 + 새로운 컨테이너 + NginX(상시 작동)가 실행되기에 인스턴스의 부하가 가중될 수 있습니다.
기본적으로 배포가 요청이 적은 시간대를 이용하여 진행되는 것을 고려하자면 큰 문제는 없어 보였습니다. 다만 혹시 모를 메모리 문제를 고려하여, Swap memory 설정을 추가하였습니다.

이를 통해 잉여 하드메모리를 프로세스에서 사용할 수 있도록 여유를 두었습니다.
2. 연결된 인프라 리소스 부족
크루루 서버와 직접적인 커넥션을 유지하고 있는 리소스를 고려하자면, 대표적으로는 RDS DB가 있습니다. 여러 인스턴스에서 동시에 업데이트를 진행한다면 발생할 수 있는 문제입니다. 하지만 현재의 무중단 배포 설계에서는 인스턴스가 2개이고, 또한 업데이트 시에도 하나씩 업데이트되므로 직접적인 문제를 발생시킬 가능성은 현저히 작아 보입니다.
그래도 해당 문제에 대하여 해결책을 고려해 보자면, 인스턴스가 많아질 경우에 병렬적으로 실행될 인스턴스의 개수를 제한하는 것이 어떨까 싶습니다.
3. DB 스키마 불일치 문제
기존 구버전의 컨테이너가 실행되고 있는 상태에서, 다른 DB 스키마를 사용하는 신버전 컨테이너가 실행된다면 불일치 문제가 발생할 수도 있습니다.
저희는 현재 DDL에 대하여 validate만 진행하고 있고, DB 테이블의 변경이 있다면 flyway로 형상 관리를 진행하고 있습니다. 따라서 DB 변경이 있는 업데이트라면 인프라 작업이 선행되어야 하며, 해당 문제는 기존 방법으로 해결될 수 있습니다.
정리
기존의 Github Actions를 이용한 동시 배포 방식에서 롤링 업데이트 방식으로 전환하였고, Github Release와 Tag를 활용하여 배포 프로세스를 개선했습니다. 또한 롤백 전략을 도입하여 배포 실패 시 안정성을 확보했습니다. 잠재적 문제로 인스턴스 리소스 부족, 인프라 리소스 부족, DB 스키마 불일치 등을 고려하고 각각에 대한 해결 방안에 대해 살펴봤습니다. 이를 통해 사용자 경험을 개선하고 안정적인 서비스 운영에 조금은 가까워지지 않았나 싶습니다.
이만 글을 마치며 다음 글로 찾아뵙겠습니다.
작성자 Github: